 I read a lot of patents, many of which may or may not apply to search engine optimization (SEO) or be used by Google at all.
I read a lot of patents, many of which may or may not apply to search engine optimization (SEO) or be used by Google at all.
But that’s not the case with the recently granted Google patent “Related entities.” I believe this patent is being applied and it gives us significant insight into how Google identifies entities and the related entities people are searching for.
Let’s look at some details I think are interesting and get a general understanding of the patent and its intent. Understanding how Google associates entities will help us grasp and use the connections to SEO.
Related entities
Let’s start with understanding related entities, especially in the context of Google patent US 20180046717A1.
If you search on the phrase “presidents of the united states,” this is what you may see:
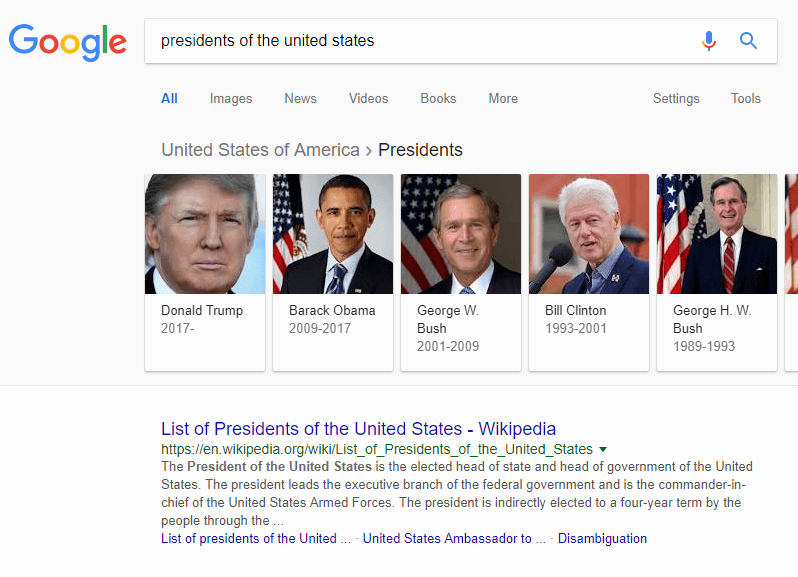
The presidents shown are “related entities” and listed because the general phrase “presidents of the united states” was searched on. Different people are shown, but all share a common denominator, being President of the United States.
How does Google know to show these particular people when a general phrase is queried? That is what the patent explains. It essentially discusses how these related entities are selected and how they are displayed.
Let’s look at another example. If we click the image of Donald Trump on the page, we are taken to a query for his name that appears as:

When I search his name without previously searching for anything President-related (and being logged out), this is what I see:

We can see the breadcrumb navigation at the top of the results which started appearing in February of 2018, but in addition, we see the context carrying forward.
When we searched for presidents, a carousel of presidents in chronological order was presented, and when we click an image, the context is carried with it, something that does not occur when we search a president in isolation.
So, what does this mean, and what does it have to do with the patent? Let’s begin by digging into a few core areas, and I will highlight the key points.
Entity database
One of my favorite takeaways is the idea there is an actual entity database.
Essentially, this is a separate database which is only tasked with understanding the various entities on the internet, what attributes they have and how they are interconnected.
For our purposes here, we need to remember that an entity is not simply a person, place or thing but also its characteristics.
These characteristics are connected by relationships. If you read a patent, the entities are referred to as “nodes,” and the relationships as “edges.” Some of the clearly prominent entities and relationships involved with Barack Obama are:
- Has name Barack Obama.
- Has position President of the United States.
- Has birthplace Honolulu Hawaii.
- Has spouse — Michelle Obama.
- Has net worth $12.1 million.
And so forth.
According to this common logic and other patents, there is a separate database outside of the general search index:

I believe this is important, and we’ll get back to it after looking at relatedness.
Determining relatedness
The patent touches on the important subject of determining relatedness.
We discussed how relatedness applies to other areas when optimizing for voice search. There are a few key ways that Google determines the relatedness of entities, but one key mechanism that comes up repeatedly is the co-occurrence of the entities in the same resources.
In our example above, this would mean the various presidents would appear on the same page often, thus indicating to Google they are related.
Alternatively, one can assume each entity appearing in the carousel would be there regardless of whether they occurred frequently or infrequently on the same page together. Even if President Jimmy Carter did not ever appear on the same page as Donald Trump, they would be associated by the phrase “president of the united states” because each man is connected to that phrase.
This is an incredibly important idea for content marketing and general SEO outside of the patent we’re discussing.
Determining priority
An area of the patent that applies less to general SEO but is still worth discussing here is that Google needs a mechanism for determining which entities and relationships are most important.
Currently, Donald J. Trump is President of the United States, but he’s also a businessman and could be connected to that entity by the relationship “has/had job.” And yet, when searching his name, we see results for him as president and not a businessman.
Here’s another example: Ronald Reagan was an actor for far longer than he was a politician or president. And yet, when we search his name, his presidential information is returned first:

Why was either man not shown as a businessman or actor when only their names were searched?
One of the key mechanisms Google uses to determine which entity and relationship are the most important is the freshness (how recent are the co-relations we discussed above), as well as the click-through rate on related queries combined with what users type in after a query.
Basically, if people typed in “president of the united states” more often than “business person” or “actor,” the importance of that relationship would be increased.
Overarching factor
Authoritative sites, especially those related to a specific subject matter, are given a higher priority in determining the relationships between entities.
For example, a Wikipedia page on Ronald Reagan that discusses his role as president would be considered authoritative and strengthen the relationship between his name and the term “president.”
If we were talking about technical SEO, Search Engine Land would be considered an authority since it is associated with the process and a flagship publication in the SEO industry.
Think of it as PageRank for entities, even though there’s no green bar to tell you when you’re on the right track.
Now, let’s look at the question, “What does this mean for SEO?”
The core of the patent
A lot of what’s in the patent applies to general SEO, and not just by displaying related options within search results.
The idea of an entity database separated from the general search system reinforced in yet another Google patent strikes a chord with me. You can think of it as a database that maps all the links across the web to pass PageRank — only more powerful.
Instead of simply keeping a record of all the links and anchors from around the web, it’s taking things one step further and includes an understanding of the relationships between entities.
If you operate a hotel in New York City, and that hotel name is frequently referenced on pages with the entity “hotel,” the relationship between the brand and the word “hotel” will be strengthened.
Further, if the hotel also exists on pages optimized for “New York City,” that entity relationship will be reinforced whether there is an active link or not. Even if topically unrelated pages use the phrase “New York City” and the name of the hotel, the relevance score goes up.
Interestingly, being included on a page with other brands that are already strongly related to New York hotels would aid your efforts as well, essentially piggy-backing on the relatedness of their brand and passing it off to yours.
And unlike PageRank, which reduces based on the number of links, I have read nothing about diminishing returns related to entities. But that isn’t to say it doesn’t happen. It’s worth considering.
Competing brands
Continuing with my hotel example, having said “hotel” on a page with competing brands would, by my logic, assist in boosting the strength of the relationship for “hotels.”
But if the page is also about dining and activities in New York, the relationship may soften.
There is no information I know of to suggest whether entity association is an on-and-off, relative-or-not scenario or whether the more entities referenced, the less any one is valued. This would make sense, and if that is the case, then pages with a focus would logically reinforce a specific entity association more than a general page.
We do know the patents suggest that proximity to an entity is a signal, so the closer two terms appear on a page, the stronger the relationship association is.
As with PageRank, authority matters. Unlike PageRank, the link doesn’t and if there’s a link. Whether it uses a nofollow attribute or not would be irrelevant.
Now, to be clear, I am referring to entity relationship building and not PageRank. PageRank and links are still powerful signals, but they are not what we’re talking about here. I’m not telling you to ignore link building or that nofollow links are as powerful as followed links, but for what we’re covering here, nofollow would not play a role.
Wikipedia uses nofollow attributes on its outbound links, yet those links pass a powerful signal.
Some might even argue sites that using nofollow links still have a high value, provided the content and structure is presented in a way that the entities can easily be associated.
Takeaways
This patent gives us some idea of how to strengthen the association of our site or brand with specific terms and entities.
The idea that we can push our rankings forward through entity associations, and not just links, is incredibly powerful and versatile. Links have tried to serve this function and have done a great job, but there are a LOT of advantages for Google to move toward the entity model for weighting as well as a variety of other internal needs.
Again, I am not suggesting you abandon your link building. Do this in addition to building links, or even better, focus your link-building efforts on ways that can accomplish both tasks at once.
If nothing else, you’ll be forcing yourself to pursue links on pages with a strong topical or geographic relevance to the attributes you want to be associated with.
Think about it this way: Even if this patent is rubbish, you’ll still be doing smart marketing.
The post Google patent on related entities and what it means for SEO appeared first on Search Engine Land.
No comments:
Post a Comment